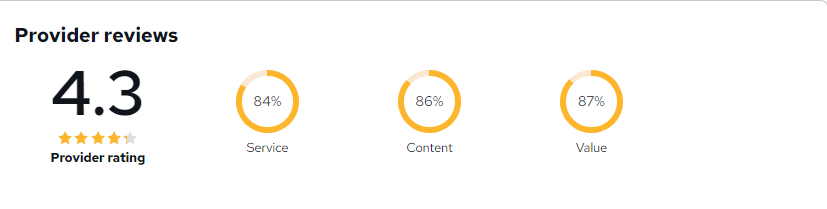
.png) 8 Reviews
8 Reviews 82 Students
82 Students Course Highlights
Course Highlights
 Learning outcome
Learning outcome
Course media
 Why should I take this course?
Why should I take this course?
 Requirements
Requirements
Course Curriculum
-
 Introduction
Introduction
 00:07:00
00:07:00 -
Building a Data-driven Organization – Introduction
-
Data Engineering
-
Learning Environment & Course Material
00:04:00
-
Movielens Dataset
00:03:00
-
Introduction to Relational Databases
00:09:00
-
SQL
00:05:00
-
Movielens Relational Model
00:15:00
-
Movielens Relational Model: Normalization vs Denormalization
00:16:00
-
MySQL
00:05:00
-
Movielens in MySQL: Database import
00:06:00
-
OLTP in RDBMS: CRUD Applications
00:17:00
-
Indexes
00:16:00
-
Data Warehousing
00:15:00
-
Analytical Processing
00:17:00
-
Transaction Logs
00:06:00
-
Relational Databases – Wrap Up
00:03:00
-
Distributed Databases
00:07:00
-
CAP Theorem
00:10:00
-
BASE
00:07:00
-
Other Classifications
00:07:00
-
Introduction to KV Stores
00:02:00
-
Redis
00:04:00
-
Install Redis
00:07:00
-
Time Complexity of Algorithm
00:05:00
-
Data Structures in Redis : Key & String
00:20:00
-
Data Structures in Redis II : Hash & List
00:18:00
-
Data structures in Redis III : Set & Sorted Set
00:21:00
-
Data structures in Redis IV : Geo & HyperLogLog
00:11:00
-
Data structures in Redis V : Pubsub & Transaction
00:08:00
-
Modelling Movielens in Redis
00:11:00
-
Redis Example in Application
00:29:00
-
KV Stores: Wrap Up
00:02:00
-
Introduction to Document-Oriented Databases
00:05:00
-
MongoDB
00:04:00
-
MongoDB Installation
00:02:00
-
Movielens in MongoDB
00:13:00
-
Movielens in MongoDB: Normalization vs Denormalization
00:11:00
-
Movielens in MongoDB: Implementation
00:10:00
-
CRUD Operations in MongoDB
00:13:00
-
Indexes
00:16:00
-
MongoDB Aggregation Query – MapReduce function
00:09:00
-
MongoDB Aggregation Query – Aggregation Framework
00:16:00
-
Demo: MySQL vs MongoDB. Modeling with Spark
00:02:00
-
Document Stores: Wrap Up
00:03:00
-
Introduction to Search Engine Stores
00:05:00
-
Elasticsearch
00:09:00
-
Basic Terms Concepts and Description
00:13:00
-
Movielens in Elastisearch
00:12:00
-
CRUD in Elasticsearch
00:15:00
-
Search Queries in Elasticsearch
00:23:00
-
Aggregation Queries in Elasticsearch
00:23:00
-
The Elastic Stack (ELK)
00:12:00
-
Use case: UFO Sighting in ElasticSearch
00:29:00
-
Search Engines: Wrap Up
00:04:00
-
Introduction to Columnar databases
00:07:00
-
HBase
00:07:00
-
HBase Architecture
00:09:00
-
HBase Installation
00:09:00
-
Apache Zookeeper
00:07:00
-
Movielens Data in HBase
00:17:00
-
Performing CRUD in HBase
00:24:00
-
SQL on HBase – Apache Phoenix
00:14:00
-
SQL on HBase – Apache Phoenix – Movielens
00:10:00
-
Demo : GeoLife GPS Trajectories
00:02:00
-
Wide Column Store: Wrap Up
00:05:00
-
Introduction to Time Series
00:09:00
-
InfluxDB
00:03:00
-
InfluxDB Installation
00:07:00
-
InfluxDB Data Model
00:07:00
-
Data manipulation in InfluxDB
00:17:00
-
TICK Stack I
00:12:00
-
TICK Stack II
00:23:00
-
Time Series Databases: Wrap Up
00:04:00
-
Introduction to Graph Databases
00:05:00
-
Modelling in Graph
00:14:00
-
Modelling Movielens as a Graph
00:10:00
-
Neo4J
00:04:00
-
Neo4J installation
00:08:00
-
Cypher
00:12:00
-
Cypher II
00:19:00
-
Movielens in Neo4J: Data Import
00:17:00
-
Movielens in Neo4J: Spring Application
00:12:00
-
Data Analysis in Graph Databases
00:05:00
-
Examples of Graph Algorithms in Neo4J
00:18:00
-
Graph Databases: Wrap Up
00:07:00
-
Introduction to Big Data With Apache Hadoop
00:06:00
-
Big Data Storage in Hadoop (HDFS)
00:16:00
-
Big Data Processing : YARN
00:11:00
-
Installation
00:13:00
-
Data Processing in Hadoop (MapReduce)
00:14:00
-
Examples in MapReduce
00:25:00
-
Data Processing in Hadoop (Pig)
00:12:00
-
Examples in Pig
00:21:00
-
Data Processing in Hadoop (Spark)
00:23:00
-
Examples in Spark
00:23:00
-
Data Analytics with Apache Spark
00:09:00
-
Data Compression
00:06:00
-
Data serialization and storage formats
00:20:00
-
SQL-on-Hadoop: Wrap Up
00:02:00
-
Introduction Big Data SQL Engines
00:03:00
-
Apache Hive
00:10:00
-
Apache Hive : Demonstration
00:20:00
-
MPP SQL-on-Hadoop: Introduction
00:03:00
-
Impala
00:06:00
-
Impala : Demonstration
00:18:00
-
PrestoDB
00:13:00
-
PrestoDB : Demonstration
00:14:00
-
SQL-on-Hadoop: Wrap Up
00:02:00
-
Data Architectures
00:05:00
-
Introduction to Distributed Commit Logs
00:07:00
-
Apache Kafka
00:03:00
-
Confluent Platform Installation
00:10:00
-
Data Modeling in Kafka I
00:13:00
-
Data Modeling in Kafka II
00:15:00
-
Data Generation for Testing
00:09:00
-
Use case: Toll fee Collection
00:04:00
-
Stream processing
00:11:00
-
Stream Processing II with Stream + Connect APIs
00:19:00
-
Example: Kafka Streams
00:15:00
-
KSQL : Streaming Processing in SQL
00:04:00
-
KSQL: Example
00:14:00
-
Demonstration: NYC Taxi and Fares
00:01:00
-
Streaming: Wrap Up
00:02:00
-
Database Polyglot
00:04:00
-
Extending your knowledge
00:09:00
-
Data Visualization
00:11:00
-
Building a Data-driven Organization – Conclusion
00:07:00
-
Conclusion
00:03:00

£25
Save 92% - Grab Now!
 All
Courses for £49
All
Courses for £49
This course includes:
-
Duration:22 hours, 22 minutes
-
Access:1 Year
-
Units:129






{kind=link}
{kind=link}